greawarz

kinkku

kasvi

bcd

greamylt

www.tumblr.com

Tzivani Rhekai

suola

Shelan Creswell

Soraya Lonescu

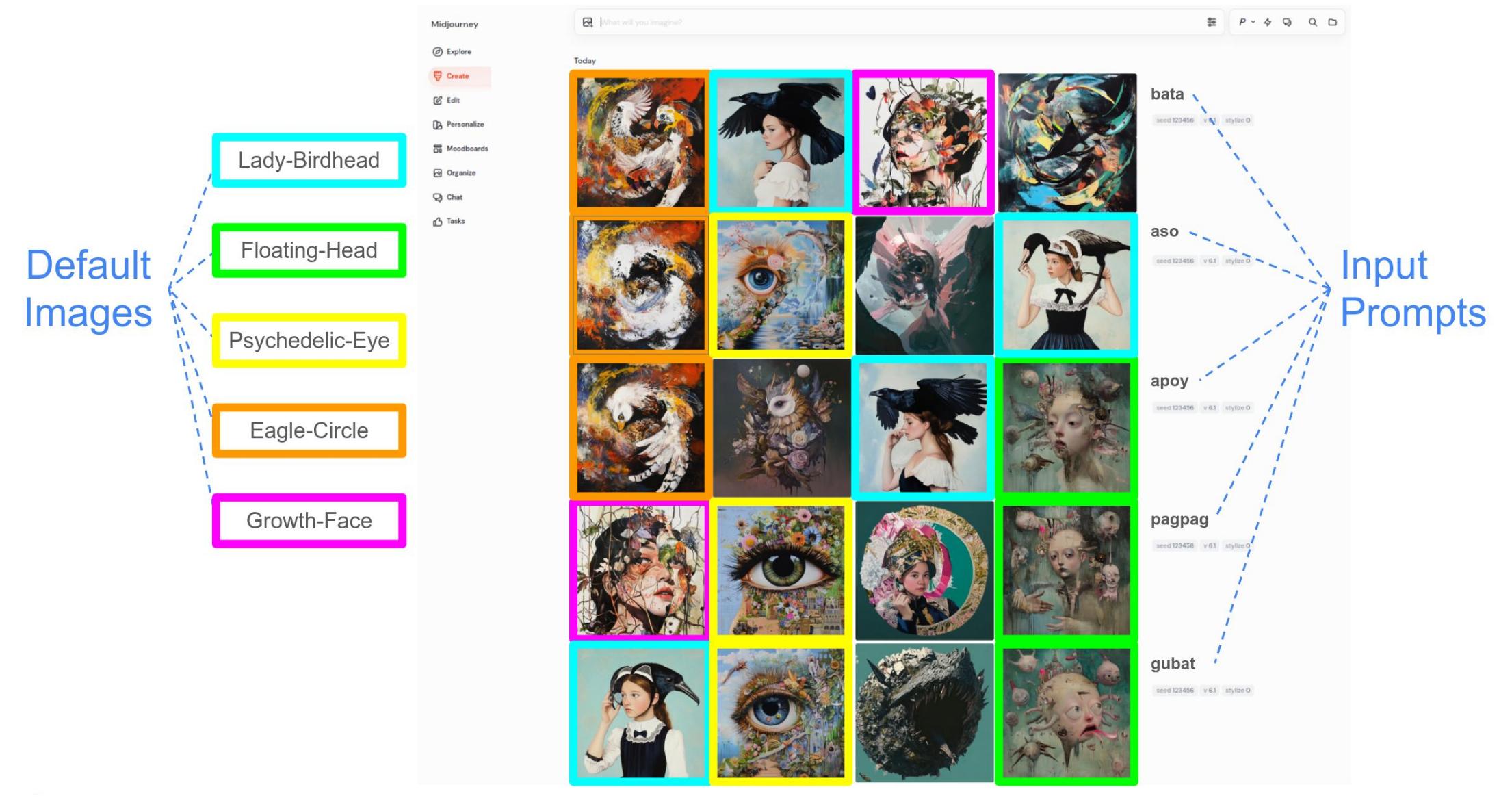
Figure 1: Default images in Midjourney. Varied, seemingly unrelated prompts lead to visually similar outputs (the "default image"), motivating our exploration of this behavior in text-to-image generation models (Midjourney).